telegram怎么搜索聊天记录
telegram 中文搜索解决方案 tg-search-lite
Description in English
Telegram has never been good at searching in non-alphabetic language (such as Chinese, Japanese, and Korean). Herein we made an offline web tool to improve the searching experience on chat history. Used data are generated by Telegram Desktop chat history exporter, in HTML.
配景
telegram官方翻译平台 新增了 简体中文 / 繁體中文 。
telegram官方终于乐意轻微关注一下中文用户了, 总的来说是件好事。 于是乎, 感觉官方支持中文搜索也 指 日 可 待 。
但现在, 想在 tg 搜索中文, 还得靠广博劳感人民的辛劳工作与不懈积极。 好比, 某些 群友 打字 带 空格, 大家 见到, 早 已经 见怪不怪 了。
官方提供数据导出工具之前(GDPR 问世前), 在下曾经做过一个 telegram 中文搜索解决方案, 叫做 tg-search , 它可以搜索某账号所能打仗到的全部数据。 而本解决方案的检索范畴(现在)较小, 一次搜索仅限于从一个 chat 中导出的数据, 故名 tg-search-lite 。
相比前作, 本解决方案充实使用官方的 html 导特别式(桌面客户端导出), 并且使用上越发和颜悦色, 普通易懂, 方便广博群众使用。
使用
以 https://t.me/Financial_Express 为例。
这是一个不停推送大量新消息的频道。 推送的速率偶然大大超越普通人的阅读速率。
对于有的browser, 直接打开 “Home.html” 可以正常运行。 好比手头的 Firefox 64.08b (Win-64bit)
但是有的browser, CORS 真的很严格, 为了 AJAX, 可以在 本机开服 , 但更建议, 暂时封闭browser的 CORS。 好比手头的 Chromium 67.0.3396.99 (32-bit) windows
暂时封闭 Chrome CORS 的教程本机开服很easy, 下个 caddy , 在文件夹 ChatExport_日_月_年 中直接开服, 再进入 http://localhost:2015/Home.html 即可。
又好比, 假如你装了 python, 在文件夹 ChatExport_日_月_年 中打开 python -m http.server , 就能进入 http://localhost:8080/Home.html 。
打开网页
然后就可以搜索了
说明
Q: 既然导出了 html, 用browser的 CTRL+F 不就好了嘛
A: 假如聊天记载在 1000 条以下, 提议 CTRL+F
但根据 tg 桌面端导特别式, 一页 (一个 html 文件) 超越 1000 条消息后, 超出部分会分到下一页, 好比第二页放在了 messages2.html 内里。 某些大群导出几百页都不希奇。 这下 CTRL+F 就不方便了。
其他可行方法, 请察看 别的方案
由于加载了两个在线资源, 以是需要联网, 如果想离线使用, 可以找动手本领强的同窗帮助把那两个在线资源下载下来, 改改路径, 应该就能离线使用了。
不需要了
初次开启时, 会占用较高 CPU / 内存。 聊天记载越多, 则用时越久, 这是由于初次运行时, 程序需要加载并剖析大量数据。
以后每次开启或刷新, 则不会 也会和第一次一样占用 CPU / 内存。 由于现在还没有做缓存的功能, 嘿嘿。
在我自己电脑上跑, Chromium 的运行速率远远落伍于 Firefox。
我也不知道为什么。 提议大家用 Firefox 运行。
初学 JS, 第一个 JS 作品。 写得很糟糕, 请包涵/请斧正。 请 PR
计划思绪 / 实现原理
由于根据官方方法导出来是 html, 以是 lite 版爽性全部用前端的方法做了。
JS 库和框架又多又乱, 让人生厌, 而 (时尚) browser的原生 API 都这么强了。 出于对 npm 和 package.json 的讨厌, 原来计划一个库都不用, 结果, jquery 真香。
在 @lxiange 的帮助下实现了一个库都不用。
大概思绪和一些详细实现参考了 docsify 和 hexo-theme-icarus 中内置的搜索插件。
加载数据, 天生索引这一步是自己想的: 用 ajax 把原始资料加载到一棵暂时的 DOM 里, 再剖析这 DOM, 录入天生搜索所需的布局化数据(索引)。
稍后增补 咕咕咕
缺点 / 后续计划
性能 :
貌似特殊吃性能。 以是提议不要搜索聊天记载太长的 chat, 量性能而行
update: 已经改进不少, 应该归功于把 jQ 的 ajax 换成browser fetch API
缓存 :
思量过将 索引缓存 存储到 LocalStorage 内里。 但是那个上限大概才 5M, 不够用。
针对 LocalStorage 太小的问题, MDN 建议了 localforage, 以后再细看。
假如容量还不够用, 思量做个实行档, 不但在当地目次天生索引文件 (一样平常就 json 了), 同时后台运行作为静态 web 服务器。 假如重心再今后点, 岂不是和旧版Telegramsearch 一样了。
以为可以试试保存一份 .json 在本文件夹
排序 :
好比搜索输入了两个词, 有一条消息中包含 1 个KeyWords 1 次, 另一条消息中包含 2 个KeyWords并且有一个KeyWords重复了 3 次。
后者表现得更靠上显然更公道。
多重 :
把多个 ChatExport 放到 ./data/ 中, 跨 chat 搜索。
需要表现某结果是从哪个 chat 中搜到。 须调整相应数据布局。
稍后增补 咕咕咕
别的方案
- grep 或类似搜索软件 (建议 ripgrep)
- 一些文本编辑器 (或类似功能软件) 的文件夹搜索
- Windows 自带搜索
- 长处: Windows 上使用方便
- 缺点: 系统版本不能太低 须开启 Windows 的文件索引服务
- 谢谢
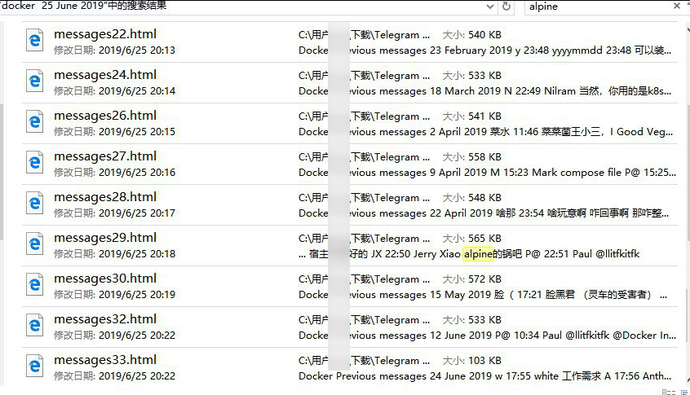
脸黑君(id 应要求隐蔽) 告知, 示比方下图
Windows Search
可以按日期找的, 打开 tgx (Android), 进入一个 chat, 右上角三点, !选第一项 search, 左下角日历图标, 选日期, 确定。
官方中日韩搜索不要幻想了, 盼了几多年, 人家从没重视过.